
[AI/Hands-on ML] - [핸즈온 머신러닝] 15장(1) - RNN과 CNN을 사용해 시퀀스 처리하기
[핸즈온 머신러닝] 15장(1) - RNN과 CNN을 사용해 시퀀스 처리하기
15. 순환 신경망 RNN - 시계열 데이터를 분석해서 주식 가격 등을 예측하고, 자율 주행 시스템에서는 차의 이동 경로를 예측하여 사고를 피하도록 도움 - 일반적으로 이 신경망은 고정 길이 입력이
kdeon.tistory.com
15. 4 긴 시퀀스 다루기
긴 시퀀스로 RNN을 훈련하려면, 많은 타임 스텝에 걸쳐 실행해야 하므로 펼친 RNN이 매우 깊은 네트워크가 됨
1. 그래디언트 소실/폭주 문제가 있을 수 있음
2. 또한 RNN이 긴 시퀀스를 처리할 때 입력의 첫 부분을 조금씩 잊어버리게됨
15. 4. 1 불안정한 그래디언트 문제와 싸우기
불안정한 그래디언트 문제를 완화하기 위해, 심층 신경망에서 사용했던 기법을 RNN에서 사용 가능
- 좋은 가중치 초기화
- 빠른 옵티마이저
- 드롭아웃
하지만 수렴하지 않는 활성화 함수는 RNN을 불안정하게 만듦
- 경사 하강법이 첫 번째 타임 스텝에서 출력을 조금 증가시키는 방향으로 가중치를 업데이트한다고 가정해보면,
- 동일한 가중치가 모든 타임 스텝에서 사용되므로 두 번째 타임 스텝의 출력도 조금 증가할 수 있고
- 그 후도 마찬가지 -> 출력이 폭주함
-> 수렴하지 않는 활성화 함수는 이를 막지 못함
-> 하이퍼볼릭 탄젠트 같은 수렴하는 활성화 함수를 사용하는 이유
배치 정규화는 심층 피드포워드 네트워크처럼 RNN과 효율적으로 사용할 수 없음
- 타임 스텝 사이에 사용할 수 없고, 순환 층 사이에만 가능함
- 엄청난 효과를 주지는 않음
-> RNN에서 잘 맞는 다른 종류의 정규화, 층 정규화
층 정규화
배치 차원에 대해 정규화하는 대신 특성 차원에 대해 정규화함
- 샘플에 독립적으로 타임 스텝마다 종적으로 필요한 통계를 계산할 수 있음
(훈련과 테스트에서 동일한 방식으로 작동한다는 것을 의미)
- 훈련 세트의 모든 샘플에 대한 특성 통계를 추정하기 위해 지수 이동 평균이 필요하지 않음
- 입력마다 하나의 스케일과 이동 파라미터를 학습함
- RNN에서 층 정규화는 보통 입력과 은닉 상태의 선형 조합 직후에 사용됨
메모리 셀 안에 층 정규화 구현
class LNSimpleRNNCell(keras.layers.Layer):
def __init__(self, units, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = keras.layers.SimpleRNNCell(units,
activation=None)
self.layer_norm = LayerNormalization()
self.activation = keras.activations.get(activation)
def get_initial_state(self, inputs=None, batch_size=None, dtype=None):
if inputs is not None:
batch_size = tf.shape(inputs)[0]
dtype = inputs.dtype
return [tf.zeros([batch_size, self.state_size], dtype=dtype)]
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]model = keras.models.Sequential([
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(LNSimpleRNNCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])15. 4. 2 단기 기억 문제 해결하기
RNN을 거치면서 데이터가 변환되므로 일부 정보는 매 훈련 스텝 후 사라짐
- 어느 정도 지나면, RNN의 상태는 사실상 첫 번재 입력의 흔적을 가지고 있지 않음
- 이는 번역같은 경우 문제가 될 수 있음
-> 장기 메모리를 가진 여러 종류의 셀이 연구됨
(요즘은 기본 셀이 많이 사용되지 않음)
LSTM 셀
Keras에서는 간단히 SimpleRNN 층 대신 LSTM 층을 사용하면 됨
model = keras.models.Sequential([
keras.layers.LSTM(20, return_sequences=True, input_shape=[None, 1]),
keras.layers.LSTM(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])또는 범용 목적의 keras.layers.RNN 층에 LSTMCell을 매개변수로 지정할 수 있음
- LSTM층이 GPU 실행 시 최적화된 구현을 사용하므로 일반적으로 선호됨
model = keras.models.Sequential([
keras.layers.RNN(keras.layers.LSTMCell(20), return_sequences=True,
input_shape=[None, 1]),
keras.layers.RNN(keras.layers.LSTMCell(20), return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])LSTM 구조
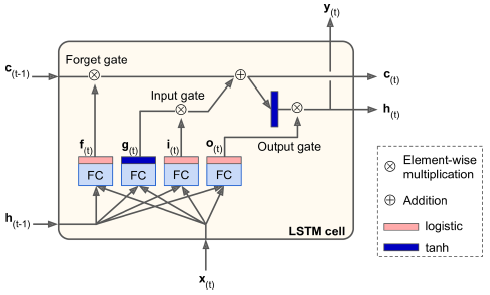
- 박스 내부를 보지 않는다면, 상태가 두 개의 벡터 h(t)와 c(t) (c는 셀을 의미) 로 나뉜다는 것을 빼고는 일반 셀과 같음
- h(t)를 단기 상태, c(t)를 장기 상태라고 할 수 있음
- 내부 구조
- 장기 기억 c(t-1)은 네트워크를 왼쪽에서 오른쪽으로 관통하면서, 삭제 게이트를 지나 일부 기억을 잃고, 그 후 덧셈 연산으로 새로운 기억 일부를 추가함(입력 게이트에서 선택한 기억을 추가함)
- 만들어진 c(t)는 다른 추가 변환 없이 바로 출력으로 보내짐
- -> 타임 스텝마다 일부 기억이 삭제되고 일부 기억이 추가됨
- 또한 덧셈 연산 후 이 장기 상태가 복사되어 tanh 함수로 전달됨
- 그 후 이 결과는 출력 게이트에 의해 걸러짐 -> 단기 상태 h(t) 생성
- 새로운 기억과 게이트의 작동
- 현재 입력 벡터 x(t)와 이전의 단기 상태 h(t-1)이 네 개의 다른 완전 연결 층에 주입됨
- 주 층은 g(t)를 출력하는 층 -> 현재 입력 x(t)와 이전의 단기 상태 h(t-1)을 분석하는 일반적인 역할 담당, 이 층의 출력이 곧 바로 나가지 않고, 장기 상태에 가장 중요한 부분이 저장됨
- 세 개의 다른 층은 게이트 제어기
- 삭제 게이트는 장기 상태의 어느 부분이 삭제되어야 하는지 제어
- 입력 게이트는 어느 부분이 장기 상태에 더해져야 하는지 제어
- 출력 게이트는 장기 상태의 어느 부분을 읽어서 이 타임스텝의 h(t)와 y(t)로 출력해야 하는지 제어
요약하자면,
- LSTM 셀은 중요한 입력을 인식하고 (입력 게이트)
- 장기 상태에 저장하고
- 필요한 기간 동안 이를 보존하고 (삭제 게이트)
- 필요할 때마다 이를 추출하기 위해 학습

- Wx* 는 입력벡터 x(t)에 각각 연결된 네 개 층의 가중치 행렬
- Wh* 는 이전의 단기 상태 h(t-1)에 각각 연결된 네 개 층의 가중치 행렬
- b*는 네 개 층 각각에 대한 편향
핍홀 연결
LSTM 셀에서 게이트 제어기는 입력 x(t)와 이전 단기 상태 h(t-1)만 바라봄
-> 게이트 제어기에 장기 상태도 노출시켜 더 많은 문맥을 감지하게 하고자함
=> 핍홀 연결 이라 부르는 추가적인 연결이 있는 LSTM 변종이 제안됨
- 이전 장기 기억 상태 c(t-1)이 삭제 게이트와 입력 게이트의 제어기 f(t)와 i(t)에 입력으로 추가됨
- 현재의 장기 기억 상태 c(t)는 출력 게이트의 제어기 o(t)에 입력으로 추가됨
-> 성능을 향상시키는 경우가 많지만, 항상 그렇지는 않음
- 케라스에서는 tf.keras.experimental.PeepholeLSTMCell 사용 가능
GRU 셀
게이트 순환 유닛 (GRU) 셀은 LSTM 셀의 간소화 버전

- 두 상태 벡터가 하나의 벡터 h(t)로 합쳐짐
- 하나의 게이트 제어기 z(t)가 삭제 게이트와 입력 게이트 모두 제어
- 게이트 제어기가 1을 출력하면 삭제 게이트가 열리고(=1) 입력 게이트가 닫힘(1-1=0)
- 게이트 제어기가 0을 출력하면 그 반대
- -> 기억이 저장될 때마다 저장될 위치가 먼저 삭제됨
- 출력 게이트가 없음
- 전체 상태 벡터가 매 타임 스텝마다 출력됨
- 이전 상태의 어느 부분이 주 층에 노출될지 제어하는 새로운 게이트 제어기 r(t)가 있음

- 케라스는 keras.layers.GRU 층을 제공함
LSTM과 GRU 셀은 RNN 성공의 주역
- 단순한 RNN보다 훨씬 긴 시퀀스를 다루지만, 매우 제한적인 단기 기억을 가짐
- 100 타임스텝 이상의 시퀀스에서 장기 패턴을 학습하는 데 어려움을 해결하기 위해, 1D 합성곱 층을 통해 입력 시퀀스를 짧게 줄일 수 있음
1D 합성곱 층을 사용해 시퀀스 처리하기
1D 합성곱 층이 몇 개의 커널을 시퀀스 위를 슬라이딩하여 커널마다 1D 특성 맵을 출력함
- 각 커널은 매우 짧은 하나의 순차 패턴을 감지하도록 학습
- 10개의 커널을 사용하면 이 층의 출력은 10개의 1차원 시퀀스로 구성됨(= 10차원 시퀀스)
=> 순환 층과 1D 합성곱 층(또는 심지어 1D 풀링 층)
앞 모델과 같도록 합성곱 층을 사용한 코드
model = keras.models.Sequential([
keras.layers.Conv1D(filters=20, kernel_size=4, strides=2, padding="valid",
input_shape=[None, 1]),
keras.layers.GRU(20, return_sequences=True),
keras.layers.GRU(20, return_sequences=True),
keras.layers.TimeDistributed(keras.layers.Dense(10))
])
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train[:, 3::2], epochs=20,
validation_data=(X_valid, Y_valid[:, 3::2]))- 스트라이드 2를 사용해 입력 시퀀스를 두 배로 다운샘플링하는 1D 합성곱층 사용
- 커널 크기가 스트라이드보다 크므로, 모든 입력을 사용해 이 층의 출력을 계산 함
-> 모델이 중요하지 않은 건 버리고, 유용한 정보를 보존하도록 학습
- 합성곱 층으로 시퀀스 길이를 줄이면, GRU 층이 더 긴 패턴을 감지하는 데 도움이 됨
-> 타깃에서 처음 세 개의 타임 스텝을 버리고 두 배로 다운 샘플해야 함
WaveNet
층마다 팽창 비율(각 뉴런의 입력이 떨어져 있는 간격)을 두 배로 늘리는 1D 합성곱 층을 쌓음
- 첫 번째 합성곱 층이 한 번에 2개의 타임 스텝만 바라봄
- 다음 층은 4개의 타임 스텝을 보고 다음은 8개의 타임 스텝을 보는 식
-> 하위 층은 단기 패턴 학습, 상위 층은 장기 패턴 학습
-> 긴 시퀀스를 매우 효율적으로 처리할 수 있음
WaveNet은 실제로 팽창 비율이 1,2,4...,512인 합성곱 층 10개를 쌓고, 동일한 층 10개를 따로 그룹지어 쌓았음
-> 이런 팽창 비율을 가진 합성곱 층 10개가 1024 크기의 커널 한 개로 이루어진 매우 효율적인 합성곱 층처럼 작동한다는 것을 보였음 (빠르고 강력, 적은 파라미터 사용)
앞과 동일한 시퀀스를 처리하는 간단한 WaveNet 구현
model = keras.models.Sequential()
model.add(keras.layers.InputLayer(input_shape=[None, 1]))
for rate in (1, 2, 4, 8) * 2:
model.add(keras.layers.Conv1D(filters=20, kernel_size=2, padding="causal",
activation="relu", dilation_rate=rate))
model.add(keras.layers.Conv1D(filters=10, kernel_size=1))
model.compile(loss="mse", optimizer="adam", metrics=[last_time_step_mse])
history = model.fit(X_train, Y_train, epochs=20,
validation_data=(X_valid, Y_valid))- 층에 추가한 패딩 덕분에, 모든 합성곱 층은 입력 시퀀스의 길이와 동일한 시퀀스를 출력
-> 훈련하는 동안 전체 시퀀스를 타깃으로 사용할 수 있음
(잘라내거나 다운샘플링할 필요가 없음)
'AI > Hands-on ML' 카테고리의 다른 글
| [핸즈온 머신러닝] 17장(1) - 오토인코더와 GAN을 사용한 표현 학습과 생성적 학습 (0) | 2021.05.17 |
|---|---|
| [핸즈온 머신러닝] 17장(2) - 합성곱 오토인코더, 순환 오토인코더, 잡음 제거 오토인코더, 희소 오토인코더 (0) | 2021.05.12 |
| [핸즈온 머신러닝] 15장(1) - RNN과 CNN을 사용해 시퀀스 처리하기 (0) | 2021.04.26 |
| [핸즈온 머신러닝] 14장(4) - CNN을 통한 위치 추정, 객체 탐지, 시맨틱 분할 (1) | 2021.04.06 |
| [핸즈온 머신러닝] 14장(3) -케라스를 통한 CNN 구현 및 모델 사용 (0) | 2021.04.03 |