
3장은 일반적인 지도 학습인 분류(클래스 예측)을 MNIST 데이터셋을 통해 집중적으로 다룸
github.com/ageron/handson-ml2/blob/master/03_classification.ipynb
- 손으로 쓴 70000개의 숫자 이미지를 모은 MNIST 데이터셋 사용
- 각 이미지는 어떤 숫자를 나타내는지 레이블이 되어 있음
- 분류 알고리즘 테스트 시 자주 사용하는 데이터셋
3.1 MNIST¶
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
mnist.keys()
- DESCR 키: 데이터셋 설명
- data 키: 샘플이 하나의 행, 특성이 하나의 열로 구성된 data 배열
- target: 레이블 배열
X,y = mnist["data"], mnist["target"]
X.shape
y.shape
- 70000개의 이미지, 각 이미지는 784개의 특성(28x28)
- 개개의 특성은 0~255까지의 픽셀 강도
import matplotlib as mpl
import matplotlib.pyplot as plt
some_digit = X[0] # feature 벡터 추출 (1x784)
some_digit_image = some_digit.reshape(28, 28) # 28x28 배열로 크기 변경
plt.imshow(some_digit_image, cmap="binary")
plt.axis("off")
plt.show()

# 실제 레이블 확인
y[0]
# 레이블 정수로 변환
import numpy as np
y = y.astype(np.uint8)
# 테스트 세트 분리
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000],y[60000:]
3.2 이진 분류기 훈련¶
- '5'만 식별하도록 훈련
- '5'와 '5 아님' 두 개의 클래스를 구분하는 이진 분류기
y_train_5 = (y_train == 5) # 5는 True, 다른 숫자는 False
y_test_5 = (y_test == 5)
- 확률적 경사 하강법(Stochastic Gradient Descent, SGD) 분류기
- 매우 큰 데이터셋을 효율적으로 처리하는 장점 (한 번에 하나씩 훈련 샘플을 독립적으로 처리하기 때문)
- 온라인 학습에 잘 맞음
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit])
3.3 성능 측정¶
- 분류기 평가는 회귀 모델보다 어려움
3.3.1 교차 검증을 통한 정확도 측정
# 사이킷런의 cross_val_score() 와 같은 작업 코드
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42)
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf) #분류기 객체(모델) 복제 후 훈련
X_train_folds = X_train[train_index]
y_train_folds = y_train_5[train_index]
X_test_fold = X_train[test_index]
y_test_fold = y_train_5[test_index]
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred))
# k-겹 교차 검증을 통해 모델 평가
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")
- 모든 이미지를 '5아님' 클래스로 분류하는 더미 분류기
- 정확도가 90%이상 (무조건 '5 아님'으로 예측해도 90% 정확도)
- => 이미지의 10%만 숫자 5 인 불균형한 데이터셋
- => 정확도를 분류기의 성능 측정 지표로 선호하지 않음
from sklearn.base import BaseEstimator
class Never5Classifier(BaseEstimator):
def fit(self, X, y=None):
return self
def predict(self, X):
return np.zeros((len(X), 1), dtype=bool)
never_5_clf = Never5Classifier()
cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring="accuracy")
3.3.2 오차 행렬
- 분류기의 성능을 평가하는 좋은 방법
- 클래스 A의 샘플이 클래스 B로 분류된 횟수를 세는 것
- 분류기가 숫자 5의 이미지를 3으로 잘못 분류한 횟수 = 오차 행렬의 5행 3열
from sklearn.model_selection import cross_val_predict
#corss_val_predict() k-겹 교차 겸증 수행, 각 테스트 폴드에서 얻은 예측 반환
#(평가 점수 반환X)
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
#오차 행렬
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
- 첫번째 행 : '5 아님' 이미지에 대한 것(음성 클래스) 53892개를 '5 아님'으로 정확히 분류(진짜 음성), 687개는 '5'라고 잘못 분류(거짓 양성)
두번째 행 : '5' 이미지에 대한 것(양성 클래스) 1891개를 '5 아님'으로 잘못 분류(거짓 음성), 3530개는 '5'라고 정확히 분류(진짜 양성)
완벽한 분류기라면 오차 행렬의 주대각선만 0이 아닌 값이 됨
3.3.3 정밀도와 재현율
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred)
# 5로 판별된 이미지 중 83%만 정확
recall_score(y_train_5, y_train_pred)
#전체 5 에 대해 65%만 정확히 5로 감지
# F1 점수 (정밀도와 재현율의 조화 평균)
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)
정밀도와 재현율이 비슷한 분류기에서 F1 점수가 높음
3.3.4 정밀도/재현율 트레이드오프
- SGDClassifier 분류기는 결정함수를 사용하여 샘플 점수 계산
- 샘플점수 > 임계값 => 샘플을 양성 클래스에 할당
- 샘플점수 < 임계값 => 샘플을 음성 클래스에 할당
사이킷런에서 임계값을 지정할 수는 없지만, 예측에 사용한 점수는 확인가능
#predict() 대신 decision_function() : 각 샘플의 점수 확인 가능
y_scores = sgd_clf.decision_function([some_digit])
y_scores
#샘플 점수를 기반으로 임계값을 정해 예측을 만들 수 있음
threshold= 0
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
threshold = 8000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred
# 임계값을 높이면 재현율이 줄어듦을 보여줌
적절한 임계값을 정하기
- cross_val_predict() 함수를 사용해 훈련 세트에 있는 모든 샘플의 점수를 구함
- 예측결과가 아닌 결정 점수를 반환받도록 지정
- precision_recall_curve() 사용해 가능한 모든 임계값에 대해 정밀도와 재현율 계산
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3,
method="decision_function")
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision", linewidth=2)
plt.plot(thresholds, recalls[:-1], "g-", label="Recall", linewidth=2)
plt.legend(loc="center right", fontsize=16) # Not shown in the book
plt.xlabel("Threshold", fontsize=16) # Not shown
plt.grid(True) # Not shown
plt.axis([-50000, 50000, 0, 1]) # Not shown
recall_90_precision = recalls[np.argmax(precisions >= 0.90)]
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]
plt.figure(figsize=(8, 4)) # Not shown
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.plot([threshold_90_precision, threshold_90_precision], [0., 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [0.9, 0.9], "r:") # Not shown
plt.plot([-50000, threshold_90_precision], [recall_90_precision, recall_90_precision], "r:")# Not shown
plt.plot([threshold_90_precision], [0.9], "ro") # Not shown
plt.plot([threshold_90_precision], [recall_90_precision], "ro") # Not shown # Not shown
plt.show()

#재현율에 대한 정밀도 곡선
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls, precisions, "b-", linewidth=2)
plt.xlabel("Recall", fontsize=16)
plt.ylabel("Precision", fontsize=16)
plt.axis([0, 1, 0, 1])
plt.grid(True)
plt.figure(figsize=(8, 6))
plot_precision_vs_recall(precisions, recalls)
plt.plot([recall_90_precision, recall_90_precision], [0., 0.9], "r:")
plt.plot([0.0, recall_90_precision], [0.9, 0.9], "r:")
plt.plot([recall_90_precision], [0.9], "ro")
plt.show()

- 재현율 80% 근처에서 정밀도가 급격하게 줄어듦
- 이 하강점 직전을 정밀도/재현율 트레이드오프로 선택
# 정밀도 90% 달성이 목표라면 최소 90% 정밀도가 되는 가장 낮은 임계값을 찾음
threshold_90_precision = thresholds[np.argmax(precisions >= 0.90)]
threshold_90_precision
# predict()대신 해당 임계값을 사용
y_train_pred_90 = (y_scores >= threshold_90_precision)
precision_score(y_train_5, y_train_pred_90)
recall_score(y_train_5, y_train_pred_90)
3.3.5 ROC 곡선
- receiver operating characteristic, 수신기 조작 특성 곡선
- 정밀도에 대한 재현율 곡선이 아닌,
- 거짓 양성 비율(FPR) 에 대한 진짜 양성 비율(TPR, 재현율) 곡선
- FPR은 양성으로 잘못 분류된 음성 샘플의 비율
- FPR = 1 - TNR(진짜 음성 비율, 음성으로 잘 분류된 음성 샘플 비율, 특이도)
- => ROC 곡선은 민감도(재현율)에 대한 (1-특이도) 그래프
#먼저 roc_curve()로 여러 임계값에서 TPR과 FPR 계산
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--') # dashed diagonal
plt.axis([0, 1, 0, 1]) # Not shown in the book
plt.xlabel('False Positive Rate (Fall-Out)', fontsize=16) # Not shown
plt.ylabel('True Positive Rate (Recall)', fontsize=16) # Not shown
plt.grid(True) # Not shown
plt.figure(figsize=(8, 6)) # Not shown
plot_roc_curve(fpr, tpr)
fpr_90 = fpr[np.argmax(tpr >= recall_90_precision)] # Not shown
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:") # Not shown
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:") # Not shown
plt.plot([fpr_90], [recall_90_precision], "ro") # Not shown # Not shown
plt.show()

- 트레이드 오프
- 재현율이 높을 수록 분류기가 만드는 거짓 양성이 늘어남
점선은 랜덤 분류기의 ROC 곡선으로, 좋은 분류기는 점선에서 최대한 멀리 떨어져 있어야함
곡선 아래의 면적(area under the curve, AUC)를 측정하면 분류기 비교 가능
- 완벽한 분류기는 ROC의 AUC가 1, 완전한 랜덤 분류기는 0.5
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)
- 양성 클래스가 드물거나 거짓 음성보다 거짓 양성이 더 중요할 때 정밀도/재현율 곡선
- 반대의 경우 ROC 곡선
- (음성에 비해 양성이 크게 적어 ROC의 AUC 점수가 좋게 나옴)
RandomForestClassifier 와 SGDClassifier 의 비교
- deicision_function() 대신 predict_proba()
- predict_proba() : 샘플이 행, 클래스가 열이며 샘플이 주어진 클래스에 속할 확률을 담은 배열 반환
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
y_probas_forest
y_scores_forest = y_probas_forest[:, 1] # 양성 클래스에 대한 확률을 점수로 사용
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
recall_for_forest = tpr_forest[np.argmax(fpr_forest >= fpr_90)]
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, "b:", linewidth=2, label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.plot([fpr_90, fpr_90], [0., recall_90_precision], "r:")
plt.plot([0.0, fpr_90], [recall_90_precision, recall_90_precision], "r:")
plt.plot([fpr_90], [recall_90_precision], "ro")
plt.plot([fpr_90, fpr_90], [0., recall_for_forest], "r:")
plt.plot([fpr_90], [recall_for_forest], "ro")
plt.grid(True)
plt.legend(loc="lower right", fontsize=16)
plt.show()

- ROC의 AUC 값이 더 큰 랜덤 포레스트 분류기가 더 좋다고 할 수 있음
roc_auc_score(y_train_5, y_scores_forest)
3.4 다중 분류¶
- 이진 분류는 두 개의 클래스 구별
- 다중 분류기(다항 분류기)는 둘 이상의 클래스 구별
- 이진 분류기를 여러개 사용해 다중 클래스를 분류하는 기법 OvR, OvA, OvO
- 다중 클래스 분류 작업에 이진 분류 알고리즘을 선택하면 사이킷런이 OvR 또는 OvO 실행
from sklearn.svm import SVC
svm_clf = SVC(gamma="auto", random_state=42)
svm_clf.fit(X_train[:1000], y_train[:1000]) # y_train, not y_train_5
svm_clf.predict([some_digit])
- 내부에서 사이킷런이 OvO 전략을 사용해 45개 이진 분류기 훈련 및 각각의 결정 점수를 얻어 점수가 가장 높은 클래스 선택
#샘플당 10개의 점수 반환
some_digit_scores = svm_clf.decision_function([some_digit])
some_digit_scores
#가정 높은 점수가 클래스 5에 해당하는 값
np.argmax(some_digit_scores)
svm_clf.classes_
svm_clf.classes_[5]
- 사이킷런에서 OvO이나 OvR을 사용하도록 강제하려면
- OneVsOneClassifier나 OneVsRestClassifier을 사용
- 이진 분류기 인스턴스를 만들어 객체 생성시 전달
# SVC 기반으로 OvR을 사용하는 다중 분류기
from sklearn.multiclass import OneVsRestClassifier
ovr_clf = OneVsRestClassifier(SVC(gamma="auto", random_state=42))
ovr_clf.fit(X_train[:1000], y_train[:1000])
ovr_clf.predict([some_digit])
len(ovr_clf.estimators_)
- SGD분류기는 직접 다중 클래스 분류가 가능
- decision_function() 메서드는 클래스마다 하나의 값 반환
sgd_clf.fit(X_train, y_train)
sgd_clf.predict([some_digit])
sgd_clf.decision_function([some_digit])
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
입력 스케일 조정해 정확도 높이기
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train.astype(np.float64))
cross_val_score(sgd_clf, X_train_scaled, y_train, cv=3, scoring="accuracy")
3.5 에러분석¶
- 가능성이 높은 모델을 찾았다고 가정하고 모델의 성능을 향상시키기 위해
- 만들어진 에러의 종류를 분석
오차 행렬
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx
def plot_confusion_matrix(matrix):
"""If you prefer color and a colorbar"""
fig = plt.figure(figsize=(8,8))
ax = fig.add_subplot(111)
cax = ax.matshow(matrix)
fig.colorbar(cax)
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()

- 대부분의 이미지기 올바르게 분류되었음을 나타내는 주대각선에 있음
- 숫자 5가 다른 숫자보다 어두움 -> 5의 이미지가 적거나 분류기가 5을 잘 분류 못함
# 오차 행렬의 각 값을 대응되는 클래스의 이미지 개수로 나누어 에러 비율 비교
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show()

- 행은 실제 클래스, 열은 예측한 클래스
- 클래스 8의 열이 밝음 = 많은 이미지가 8로 잘못 분류되었음
- 클래스 8의 행은 나쁘지 않음 = 실제 8은 적절히 8로 분류되었음
3과 5 또한 서로 혼동되고 있음
8로 잘못 분류되는 것을 줄이도록 개선
- 8처럼 보이지만 8이 아닌 숫자 데이터를 많이 모아 학습
- 동심원 수를 세는 알고리즘 같은 새 특성을 찾아 추가함
# EXTRA
def plot_digits(instances, images_per_row=10, **options):
size = 28
images_per_row = min(len(instances), images_per_row)
images = [instance.reshape(size,size) for instance in instances]
n_rows = (len(instances) - 1) // images_per_row + 1
row_images = []
n_empty = n_rows * images_per_row - len(instances)
images.append(np.zeros((size, size * n_empty)))
for row in range(n_rows):
rimages = images[row * images_per_row : (row + 1) * images_per_row]
row_images.append(np.concatenate(rimages, axis=1))
image = np.concatenate(row_images, axis=0)
plt.imshow(image, cmap = mpl.cm.binary, **options)
plt.axis("off")
cl_a, cl_b = 3, 5
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]
plt.figure(figsize=(8,8))
plt.subplot(221); plot_digits(X_aa[:25], images_per_row=5)
plt.subplot(222); plot_digits(X_ab[:25], images_per_row=5)
plt.subplot(223); plot_digits(X_ba[:25], images_per_row=5)
plt.subplot(224); plot_digits(X_bb[:25], images_per_row=5)
plt.show()

- 왼쪽 블록 두개는 3으로 분류된 이미지
오른쪽 블록 두개는 5로 분류된 이미지
선형 분류기 SGDClassifier
- 클래스마다 픽셀에 가중치를 할당하고 새로운 이미지에 대해 단순히 픽셀 강도의 가중치 합을 클래스 점수로 계산
- 3과 5는 몇개의 픽셀만 다르기 때문에 모델이 쉽게 혼동
3.6 다중 레이블 분류¶
- 분류기가 샘플마다 여러개의 클래스를 출력해야하는 경우
- 한 사진에 앨리스, 밥, 찰리 세 얼굴을 인식하도록 훈련하면 분류기가 [1,0,1]을 출력해야함
- 여러 개의 이진 꼬리표를 출력하는 분류 시스템
- 각 숫자 이미지에 두 개의 타깃 레이블이 담긴 y_multilabel 배열을 만듦
- 첫번째는 숫자가 큰 값(7,8,9)인지 나타내고
- 두번째는 홀수인지 나타냄
- 다중 타깃 배열을 사용하여 훈련
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([some_digit])
- 숫자 5는 크지않고(False), 홀수(True)
다중 레이블 분류기 평가
- 모든 레이블에 대한 F1 점수의 평균
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
f1_score(y_multilabel, y_train_knn_pred, average="macro")
3.7 다중 출력 분류¶
다중 출력 다중 클래스 분류 (다중 출력 분류)
- 다중 레이블 분류에서 한 레이블이 다중 클래스가 될 수 있도록 일반화
이미지 잡음 제거 시스템
- 깨끗한 숫자 이미지를 MNIST 이미지처럼 픽셀의 강도를 담은 배열로 출력
- 분류기의 출력이 다중 레이블(픽셀당 한 레이블)이고 각 레이블은 값을 여러개(0~255 픽셀 강도) 가짐
# 이미지 픽셀 강도에 잡음 추가
noise = np.random.randint(0, 100, (len(X_train), 784))
X_train_mod = X_train + noise
noise = np.random.randint(0, 100, (len(X_test), 784))
X_test_mod = X_test + noise
y_train_mod = X_train
y_test_mod = X_test
def plot_digit(data):
image = data.reshape(28, 28)
plt.imshow(image, cmap = mpl.cm.binary,
interpolation="nearest")
plt.axis("off")
some_index = 0
plt.subplot(121); plot_digit(X_test_mod[some_index])
plt.subplot(122); plot_digit(y_test_mod[some_index])
plt.show()

knn_clf.fit(X_train_mod, y_train_mod)
clean_digit = knn_clf.predict([X_test_mod[some_index]])
plot_digit(clean_digit)

추가 설명
3.3.1. 교차 검증을 사용한 정확도 측정
StratifiedKFold를 이용한 교차 검증 구현
stratified 는 label의 분포를 유지시켜줌
각 fold 안의 데이터셋의 label 분호가 전체 데이터 셋의 label 분포를 따르기 때문에,
각 fold가 전체 데이터셋을 잘 대표한다.
즉, 모델을 학습시킬 때 편항되지 않게 학습시킬 수 있다.
3.3.2. 오차 행렬
오차 행렬이 많은 정보를 제공해주지만 가끔 더 요약된 지표가 필요할 수도 있음
양성 예측의 정확도, 분류기의 정밀도
정밀도(predicision)
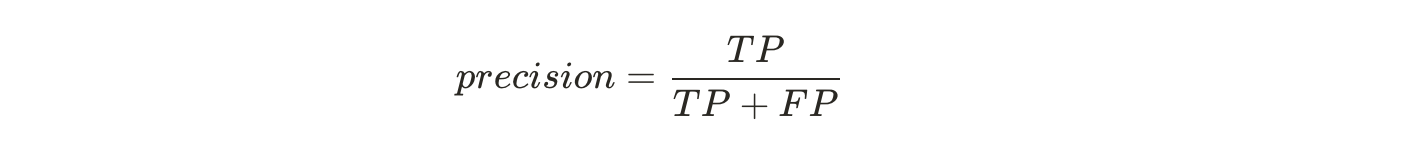
'5'라고 분류된 것들 중, 실제 '5'인 비율
양성 샘플 하나만 예측하면 간단히 완벽잔 정밀도를 얻지만,
이는 분류기가 다른 모든 양성 샘플을 무시하기 때문에 유용X
정밀도는 재현율이라는 지표과 같이 사용하는 것이 일반적
재현율은 분류기가 정확하게 감지한 양성 샘플의 비율
(민감도, 진짜 양성 비율)
재현율(recall)
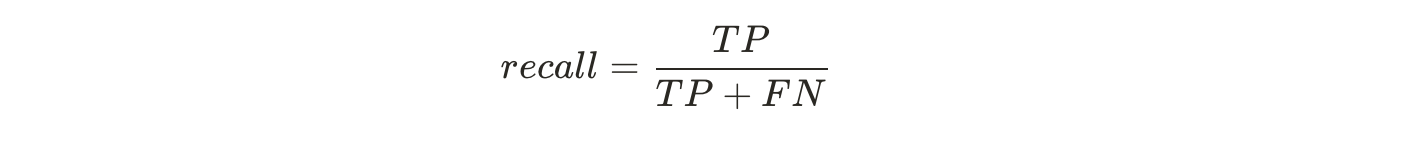
실제 '5' 이미지에 대해, '5' 라고 정확히 분류된 것의 비율
F1 점수 = 정밀도와 재현율의 조화 평균
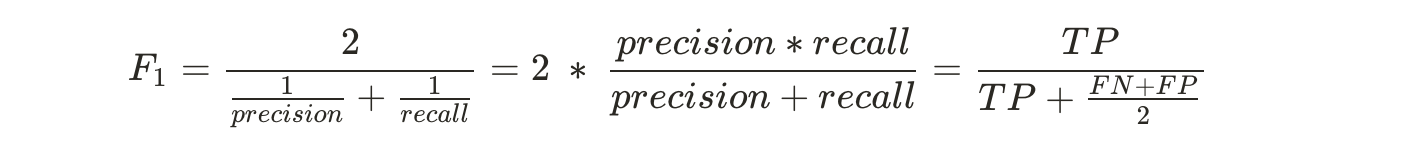
어린아이에게 안전하다고 판별된 동영상 중 실제로 안전한 동영상인 비율(정밀도)
실제 안전한 동영상에 대해. 안전하다고 정확히 분류된 비율(재현율)
재현율은 낮더라도, 정밀도가 높은 것 선호
(안전한 동영상이 나쁘게 판별되는 것이 더 나음)
좀도둑이라고 분류된 것들 중 실제로 좀도둑 이미지인 비율(정밀도)
실제 좀도둑 이미지에 대해, 좀도둑이라고 분류된 것의 비율(재현율)
정밀도는 낮더라도, 재현율이 높은 것 선호
정밀도를 올리면 재현율이 줄고, 재현율을 올리면 정밀도가 줄어드는
정밀도/재현율 트레이드오프 존재
3.3.4 정밀도/재현율 트레이드오프
- SGDClassifier 분류기는 결정함수를 사용하여 샘플 점수 계산
- 샘플점수 > 임계값 => 샘플을 양성 클래스에 할당
- 샘플점수 < 임계값 => 샘플을 음성 클래스에 할당
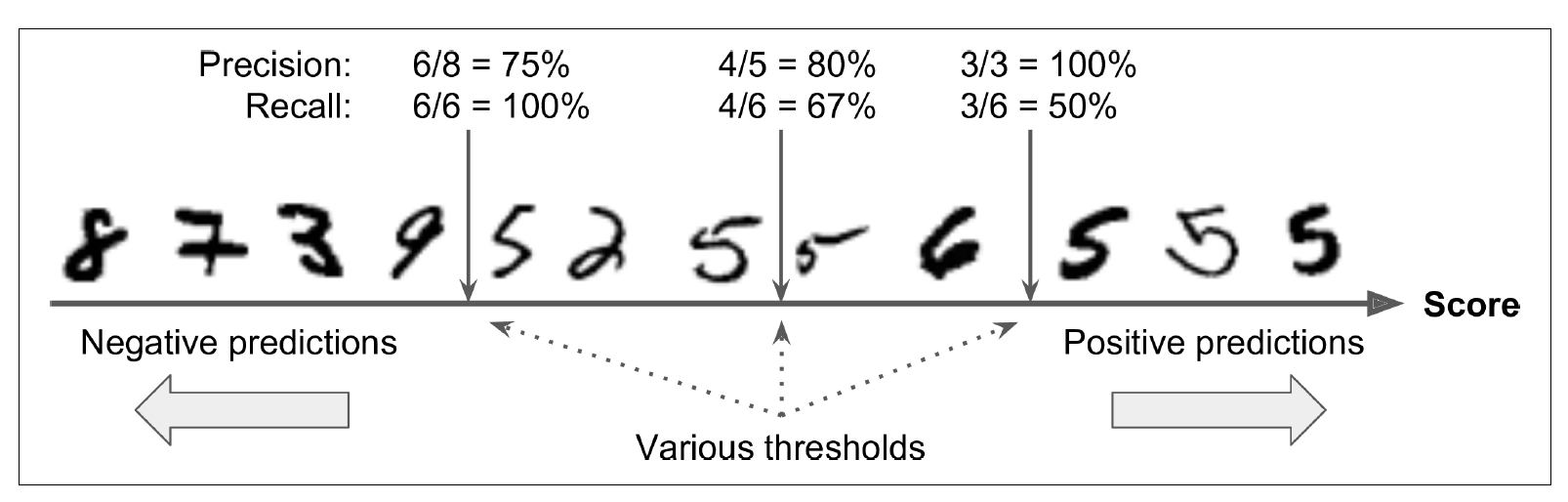
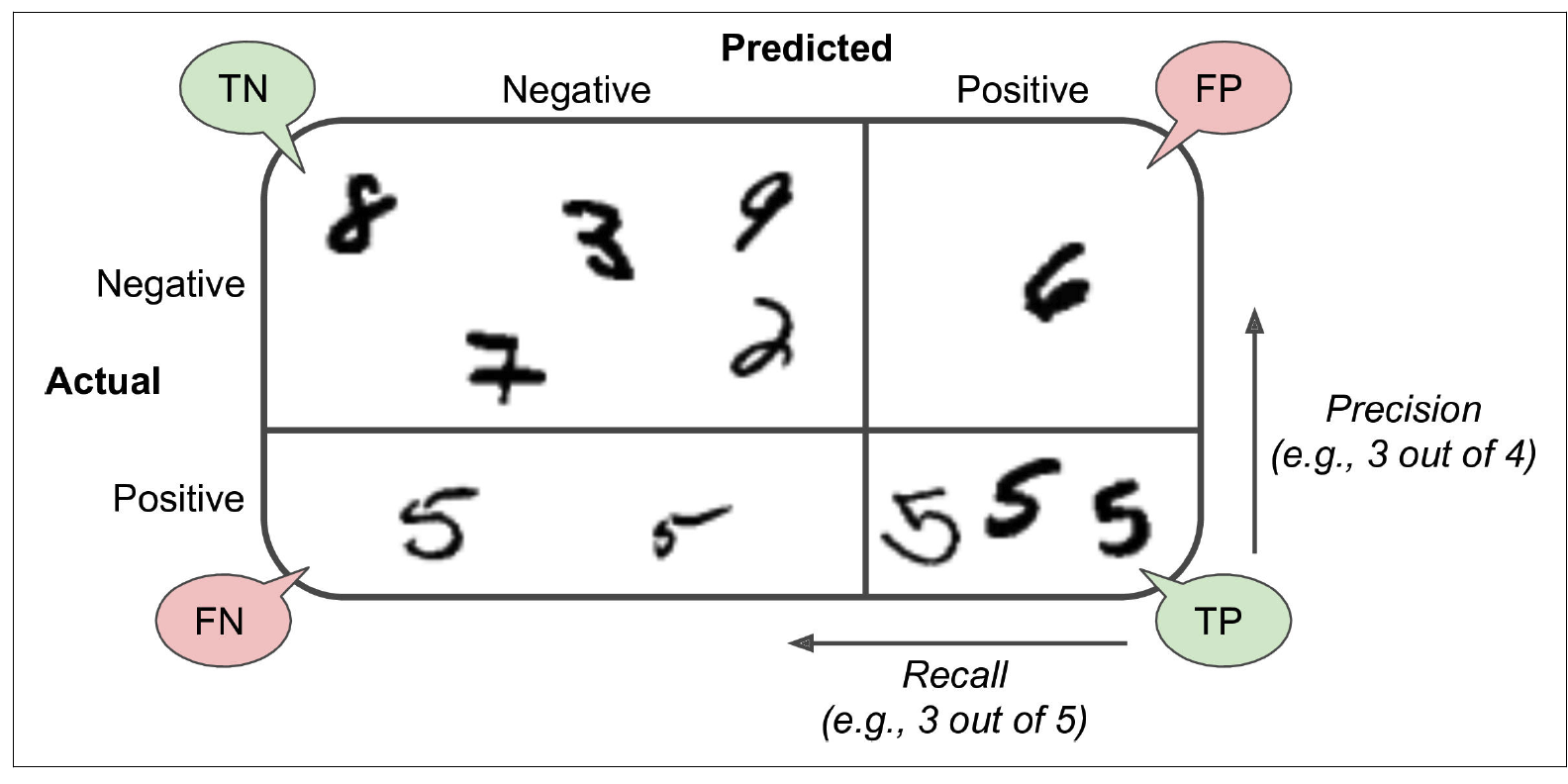
결정 임계값이 가운데 화살표일 경우,
임계값 오른쪽에 4개의 진짜 양성(실제 5)과 하나의 거짓양성(6)이 있으므로
이 임계값에서 정밀도는 80%(4/5)
실제 숫자 5는 총 6개고 분류기는 4개를 5라고 감지했으므로
재현율은 67%(4/6)
임계값을 높이면 거짓양성이 진짜 음성이 되어 정밀도가 높아지고,
진짜 양성 하나가 거짓음성이 되었으므로 재현율이 50%로 줄어듦
반대로 임계값을 내리면 재현율은 높아지고, 정밀도는 줄어듦
3.4 다중 분류
- 이진 분류는 두 개의 클래스 구별
- 다중 분류기(다항 분류기)는 둘 이상의 클래스 구별
이진 분류기를 여러개 사용해 다중 클래스를 분류하는 기법
EX_1)특정 숫자 하나만 구분하는 숫자별 이진 분류기 10개(0~9)를 훈련시켜
클래스 10개인 숫자 이미지 분류 시스템을 만드는 방법
(이미지를 분류할 때 각 분류기의 결정 점수 중에서 가장 높은 것을 클래스로 선택)
이를 OvR(one-versus-the-rest) 전략, 또는 OvA(one-versus-all) 라고 함.
EX_2) 0과 1 구별, 0과 2 구별 등과 같이 숫자 조합마다 이진 분류기를 훈련시키는 것.
이를 OvO(one-versus-one)라고 함.
클래스가 N개라면 분류기는 N*(N-1)/2 개가 필요함. (MNIST 는 45개의 분류기를 훈련)
이미지 하나를 분류하려면 45개 분류기를 모두 통과시켜 가장 많이 양성으로 분류된 클래스 선택
각 분류기 훈련에 전체 훈련 세트 중 구별할 두 클래스에 해당하는 샘플만 필요하다는 것이 장점
대부분의 이진 분류 알고리즘은 OvR을 선호
서포트 벡터 머신같은 훈련 세트의 크기에 민감한 알고리즘은 OvO 선호
'AI > Hands-on ML' 카테고리의 다른 글
| [핸즈온 머신러닝] 핸즈온 머신러닝2 정오표 (0) | 2021.01.22 |
|---|---|
| [핸즈온 머신러닝] 7장 - 앙상블 학습과 랜덤 포레스트 (0) | 2021.01.19 |
| [핸즈온 머신러닝] 6장 - 결정 트리 (0) | 2021.01.03 |
| [핸즈온 머신러닝] 5장 - 서포트 벡터 머신 (0) | 2021.01.03 |
| [핸즈온 머신러닝] 4장 - 모델 훈련 (0) | 2020.12.08 |