[핸즈온 머신러닝] 10장 - 케라스를 사용한 인공 신경망 2 (케라스로 딥러닝하기)
[AI/Hands-on ML] - [핸즈온 머신러닝] 10장 - 케라스를 사용한 인공 신경망 (인공 신경망 소개)
[핸즈온 머신러닝] 10장 - 케라스를 사용한 인공 신경망 (인공 신경망 소개)
10. 인공 신경망 인공 신경망 뇌에 있는 생물학적 뉴런의 네트워크에서 영감을 받은 머신러닝 모델 - 하지만 생물학적 뉴런(신경 세포)에서 점점 멀어지고 있음 - 딥러닝의 핵심이며, 복잡한 대규
kdeon.tistory.com
10. 2 케라스로 다층 퍼셉트론 구현하기
텐서플로의 자체적 케라스 구현인 tf.keras를 통한 실습
10. 2. 2 시퀀셜 API를 사용하여 이미지 분류기 만들기
데이터 적재
import tensorflow as tf
from tensorflow import keras
keras.__version__=> 2.4.0
fashion_mnist = keras.datasets.fashion_mnist
(X_train_full, y_train_full), (X_test, y_test) = fashion_mnist.load_data()
X_train_full.shape
X_train_full.dtype=> (60000, 28, 28)
=> dtype('uint8')
# 검증 세트 생성
# 입력 특성의 스케일 조정(경사하강법을 통한 신경망 훈련을 위해)
# -> 픽셀 강도를 255.0 으로 나누어 0~1 범위로 조정
X_valid, X_train = X_train_full[:5000] / 255., X_train_full[5000:] / 255.
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.# 레이블에 해당하는 아이템을 나타내기 위해 클래스 이름 리스트 생성
class_names = ["T-shirt/top", "Trouser", "Pullover", "Dress", "Coat",
"Sandal", "Shirt", "Sneaker", "Bag", "Ankle boot"]
class_names[y_train[0]]=> 'Coat'
신경망 생성
- 두 개의 은닉층으로 이루어진 분류용 다층 퍼셉트론
# 신경망 생성
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))-
Sequential 모델 생성
-
가장 간단한 케라스의 신경망 모델으로, 순서대로 연결된 층을 일렬로 쌓아서 구성함 => 시퀀셜 API
-
-
첫 번째 층을 만들고 모델에 추가
-
Flatten 층은 입력 이미지를 1D 배열로 변환함. 즉, 입력 데이터 X를 받으면 X.reshape(-1, 28*28)을 계산함
- 이 층은 어떤 모델 파라미터도 가지지 않고 간단한 전처리를 수행할 뿐
- 모델의 첫 번째 층이므로 input_shape을 지정해야 함 - 배치 크기를 제외하고 샘플 크기만 써야 함
- 첫 번째 층으로 input_shpe=[28, 28]로 지정된 kera.layer.InputLayer 층을 추가할 수도 있음
-
-
뉴런 300개를 가진 Dense 은닉층을 추가
-
이 층은 ReLU 활성화 함수를 사용함
-
Dense 층마다 각자 가중치 행렬을 관리함
-
이 행렬에는 층의 뉴런과 입력 사이의 모든 연결 가중치가 포함됨
-
또한 뉴런마다 하나씩 있는 편향도 벡터로 관리함
-
이 층은 입력 데이터를 받으면 앞서 봤던 '완전 연결 층의 출력 계산' 식을 계산 함
-
-
뉴런 100개를 가진 두 번째 Dense 은닉층을 추가함
-
ReLU 활성화 함수를 사용함
-
-
마지막으로 클래스마다 하나씩 뉴런 10개를 가진 Dense 출력층을 추가함
-
배타적인 클래스이므로 소프트맥스 활성화 함수를 사용함
-
아래와 같이 Sequential 모델을 만들 때 층의 리스트를 전달할 수도 있음
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])# 모델 layer 확인
model.summary()=>
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param # =================================================================
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 300) 235500
_________________________________________________________________
dense_1 (Dense) (None, 100) 30100
_________________________________________________________________
dense_2 (Dense) (None, 10) 1010 =================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
- Dense 층은 보통 많은 파라미터를 가짐 -> 예를 들어 첫 번째 은닉층은 784*300개의 연결 가중치와 300개의 편향을 가짐 => 이를 더하면 파라미터가 235,500 개가 됨
- 이런 모델은 훈련 데이터를 학습하기 충분한 유연성을 가짐 (또한 과대적합의 위험을 가짐, 특히 훈련 데이터가 많지 않을 경우)
model.layers=> [<tensorflow.python.keras.layers.core.Flatten at 0x1e5ba7a46a0>, <tensorflow.python.keras.layers.core.Dense at 0x1e5ba7c81f0>, <tensorflow.python.keras.layers.core.Dense at 0x1e5baa92fa0>, <tensorflow.python.keras.layers.core.Dense at 0x1e5baa92f10>]
hidden1 = model.layers[1]
hidden1.name=> 'dense'
model.get_layer('dense') is hidden1=> True
각 층의 모든 파라미는 가중치와 편향 확인 가능
weights, biases = hidden1.get_weights()
weights=>
array([[ 0.01173569, 0.04237127, 0.061399 , ..., -0.07112142, -0.01814937, -0.05381333], [ 0.06332901, -0.00643114, -0.01675814, ..., 0.02386014, 0.06778005, 0.04085486], [ 0.06377356, -0.03350462, 0.04519348, ..., -0.06329179, -0.06856172, -0.01023558], ..., [ 0.00242883, 0.03840162, -0.00195624, ..., 0.04776923, -0.03343857, -0.00767276], [-0.0392911 , -0.03368513, -0.06466423, ..., -0.03613435, 0.06715587, -0.03098493], [-0.04369525, -0.07398814, -0.00486762, ..., 0.01618735, -0.03390044, 0.04854329]], dtype=float32)
weights.shape=> (784, 300)
biasesarray([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0 ... , 0., 0., 0.], dtype=float32)
biases.shape=> (300,)
Dense 층은 앞서 언급한 대칭성을 깨뜨리기 위해 연결 가중치를 무작위로 초기화함
- 편향은 0으로 초기화함
- 다른 초기화 방법을 사용하고 싶다면 층을 만들때 kernel_initializer 와 bias_initializer 매개변수 설정
-(kernel 은 연결 가중치 행렬의 또 다른 이름임)
모델 컴파일
손실 함수와 옵티마지어 지정
- 부가적으로 훈련과 평가 시에 계산할 지표를 추가로 지정할 수 있음
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])위 코드는 아래와 동일
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
optimizer=keras.optimizers.SGD(),
metrics=[keras.metrics.sparse_categorical_accuracy])-
레이블이 정수 하나로 이루어져 있음 (샘플마다 타깃 클래스 인덱스가 하나 있음, 여기서는 0~9의 정수)
-
클래스가 배타적이므로 sparse_catergoical_crossentropy 손실을 사용함
-
샘플마다 클래스 별 타깃 확률을 가지고 있다면
-
ex. 클래스 3이 [0., 0., 0., 1., 0., 0., 0., 0., 0., 0. ] 인 원-핫 벡터라면
-
categorical_crossentropy 손실을 사용해야 함
-
이진 분류나 다중 레이블 이진 분류를 수행한다면 출력층에 softmax대신 sigmoid 함수를 사용하고 binary_crossentropy 손실을 사용함
-
-
옵티마이저에 sgd를 지정하면 기본 확률적 경사 하강법을 사용하여 모델을 훈련한다는 의미
-
케라스가 역전파 알고리즘을 수행 함 - 후진 모드 자동 미분과 경사 하강법
-
SGD 옵티마이저를 사용할 때 학습률을 튜닝하는 것이 중요 - 기본값 lr=0.01 사용
-
-
분류기이므로 훈련/평가 시에 정확도 측정을 위해 accuracy 로 지정
모델 훈련과 평가
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid))=>
Epoch 1/30 1719/1719 [==============================] - 3s 1ms/step - loss: 1.0266 - accuracy: 0.6749 - val_loss: 0.5304 - val_accuracy: 0.8196
Epoch 2/30 1719/1719 [==============================] - 2s 1ms/step - loss: 0.5117 - accuracy: 0.8223 - val_loss: 0.4408 - val_accuracy: 0.8546
....
Epoch 30/30 1719/1719 [==============================] - 2s 970us/step - loss: 0.2298 - accuracy: 0.9168 - val_loss: 0.3001 - val_accuracy: 0.8898
- epoch이 끝날 때마다 검증 세트를 사용해 손실과 추가적인 측정 지표를 계산
=> 모델이 얼마나 잘 수행되는지 확인하는 데 유용
- 훈련 세트 성능이 검증 세트보다 월등히 높다면 모델이 훈련 세트에 과대적합되었을 것
- 훈련 epoch마다 케라스는 다음 정보를 출력함
-
처리한 샘플 개수
-
샘플마다 걸린 평균 훈련 시간
-
훈련 세트와 검증세트에 대한 손실과 정확도 (또는 추가로 요청한 다른 지표)
=> 훈련 손실이 감소하고, 30 epoch 이후에 검증 정확도가 89.26%에 도달했으므로 (훈련 정확도와 차이가 크지 않음) 과대적합이 많이 일어나지 않은 결과
어떤 클래스는 많이 등장하고, 다른 클래스는 조금 등장하여 훈련 세트가 편중되어 있다면
fit() 메서드에 class_weight 매개변수를 지정
- 적게 등장하는 클래스는 높은 가중치, 많이 등장하는 클래스는 낮은 가중치를 부여함
- 샘플별로 가중치 부여시 sample_weight 매개변수를 지정
- 둘다 지정되면 케라스는 두 값을 곱하여 사용
- 어떤 샘플은 전문가에 의해 레이블이 할당되고, 다른 샘플은 클라우드 소싱 플랫폼을 사용해 할당되었다면, 전자에 높은 가중치를 부여할 것
- validation_data 튜플의 세 번째 원소로 검증 세트에 대한 샘플별 가중치를 지정할 수도 있음
history 객체를 사용한 학습 곡선 확인
- history.hostroy에는 epoch이 끝날 때마다 훈련 세트와 검증 세트에 대한 손실과 측정한 지표가 담겨있음
import pandas as pd
import matplotlib.pyplot as plt
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
# save_fig("keras_learning_curves_plot")
plt.show()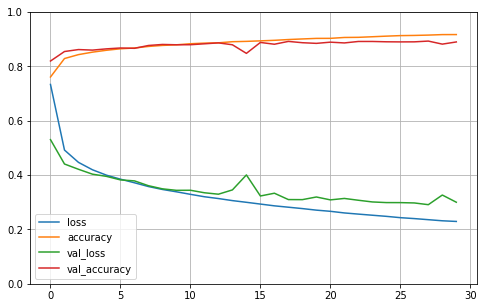
- 검증 곡선이 훈련 곡선과 가까움 - 크게 과대적합되지 않았음
- 훈련 초기에 모델이 훈련 세트보다 검증 세트에서 더 좋은 성능을 낸 것 처럼 보이지만, 검증 손실은 epoch이 끝난 후에 계산되고 훈련 손실은 epoch이 진행되는 동안 계산됨
-
훈련 속선은 epoch의 절반만큼 왼쪽으로 이동해야함
-
그렇게 보면 훈련 초기에 훈련 곡선과 검증 곡선이 일치함
- 보통 충분히 오래 훈련하면, 훈련 세트의 성능이 검증 세트의 성능을 앞지름
- 검증 손실이 여전히 감소한다면 모델은 아직 완전히 수렴되지 않았으므로 훈련을 계속해야함
- 케라스는 fit() 메서드를 다시 호출 시 중지되었던 곳에서 훈련을 이어감
- 모델 성능에 만족스럽지 않으면 처음으로 돌아가 하이퍼파라미터 튜닝을 해야함
- 학습률부터 확인
- 학습률이 도움이 안되면, 다른 옵티마이저를 테스트
- 항상 다른 하이퍼파라미터를 바꾼 후에는 학습률을 다시 튜닝해야 함
- 층 개수, 층에 있는 뉴런 개수, 은닉층이 사용하는 활성화 함수 등 모델의 하이퍼파라미터 튜닝 가능
- 배치 크기같은 하이퍼파라미터 튜닝 가능
모델의 검증 정확도가 만족스러우면, 테스트 세트로 모델을 평가해 일반화 오차를 추정
model.evaluate(X_test, y_test)=>
313/313 [==============================] - 0s 750us/step - loss: 0.3309 - accuracy: 0.8812
[0.3309190571308136, 0.8812000155448914]
- 검증 세트보다 테스트 세트에서 성능이 조금 낮은 것이 일반적임
- 하이퍼파라미터를 튜닝한 곳이 테스트 세트가 아니라 검증 세트이기 때문
모델을 사용해 예측을 만들기
X_new = X_test[:3]
y_proba = model.predict(X_new)
y_proba.round(2)=> array([[0. , 0. , 0. , 0. , 0. , 0.01, 0. , 0.02, 0. , 0.97], [0. , 0. , 0.99, 0. , 0.01, 0. , 0. , 0. , 0. , 0. ], [0. , 1. , 0. , 0. , 0. , 0. , 0. , 0. , 0. , 0. ]], dtype=float32)
- 샘플에 대해 클래스마다 각각의 확률을 모델이 추정하였음
- 첫 번째 이미지 - 클래스 9 앵클부츠의 확률이 가장 높음, 다른 클래스의 확률을 보면, 신발 종류라고 믿고 있음
import numpy as np
#y_pred = model.predict_classes(X_new) # deprecated
y_pred = np.argmax(model.predict(X_new), axis=-1)
y_pred=> array([9, 2, 1], dtype=int64)
np.array(class_names)[y_pred]=> array(['Ankle boot', 'Pullover', 'Trouser'], dtype='<U11')
# 앞서 분류한 이미지 확인
y_new = y_test[:3]
y_new=> array([9, 2, 1], dtype=uint8)
10. 2. 3 시퀀셜 API를 사용하여 회귀용 다층 퍼셉트론 만들기
캘리포니아 주택 가격 데이터셋으로 회귀 신경망 실습
- 이 데이터셋은 수치 특성만 있으므로 2장에서 사용한 것보다 간단 (ocean_proximity 특성 없음)
- 누락된 데이터도 없음
데이터 적재 후 훈련 세트, 검증 세트, 테스트 세트로 나누고 모든 특성의 스케일 조정
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(housing.data, housing.target, random_state=42)
X_train, X_valid, y_train, y_valid = train_test_split(X_train_full, y_train_full, random_state=42)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)시퀀셜 API를 사용해 회귀용 MLP를 구축, 훈련, 예측하는 방법은 분류에서 했던 것과 매우 비슷
- 차이점은 출력층이 활성화 함수가 없는 하나의 뉴런을 가지고 (하나의 값을 예측하기 때문)
- 손실 함수로 평균 제곱 오차를 사용한다는 것
이 데이터셋은 잡음이 많기 때문에 과대적합을 막는 용도로 뉴런 수가 적은 은닉층 하나만 사용
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1)
])
model.compile(loss="mean_squared_error", optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit(X_train, y_train, epochs=20, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
X_new = X_test[:3]
y_pred = model.predict(X_new)
Sequential 모델이 매우 널리 사용되지만 입력과 출력이 여러 개 거나 더 복잡한 네트워크 토폴로지를 갖는 신경망을 만들 경우 함수형 API 사용
10. 2. 4 함수형 API를 사용해 복잡한 모델 만들기
와이드 & 딥 신경망 : 순차적이지 않은 신경망의 한 예
- 이 신경망 구조는 2016년 헝쯔 청의 논문에서 소개됨
- 입력의 일부 또는 전체가 출력층에 바로 연결 됨
- 이 구조를 사용하면 신경망이 (깊게 쌓은 층을 사용한) 복잡한 패턴과 (짧은 경로를 사용한) 간단한 규칙을 모두 학습할 수 있음
- 이와 대조적으로 일반적인 MLP는 네트워크에 있는 층 전체에 모든 데이터를 통과시킴
(데이터에 있는 간단한 패턴이 연속된 변환으로 인해 왜곡될 수 있음)
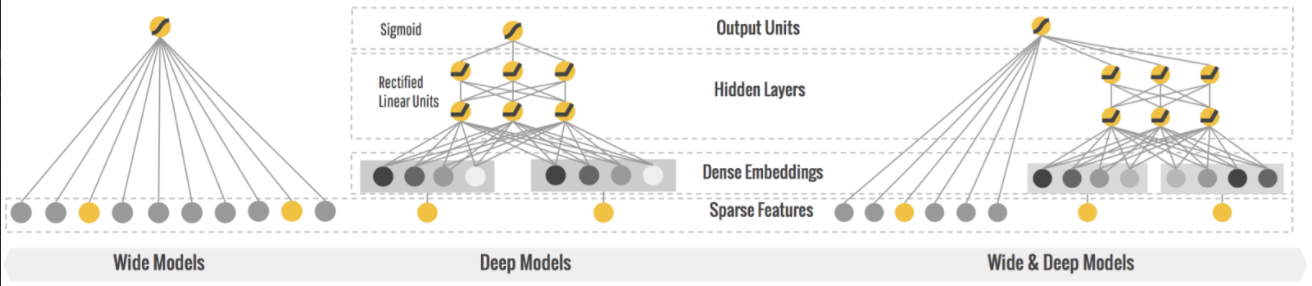
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.models.Model(inputs=[input_], outputs=[output])-
Input 객체 생성 - 이 객체는 shape과 dtype을 포함하여 모델의 입력을 정의 - 한 모델은 여러 개의 입력을 가질 수 있음
-
30개 뉴런과 ReLU 활성화 함수를 가진 Dense 층을 만듦 - 입력과 함께 함수처럼 호출됨
-
두번 째 은닉층을 만들고 함수처럼 호출 - 첫 번째 층의 출력을 전달
-
Concantenate 층을 만들고 함수처럼 호출하여 두 번째 은닉층의 출력과 입력을 연결
-
하나의 뉴런과 활성화 함수가 없는 출력층을 만들고 Concatenate 층이 만든 결과를 사용해 호출
-
마지막으로 사용할 입력과 출력을 지정하여 케라스 Model을 만듦
일부 특성은 짧은 경로로 전달하고 다른 특성들은 깊은 경로로 전달하고 싶은 경우
- 여러 입력을 사용함
- 5개 특성을 짧은 경로로 보내고 6개의 특성을 깊은 경로로 보낸다고 가정
input_A = keras.layers.Input(shape=[5], name="wide_input")
input_B = keras.layers.Input(shape=[6], name="deep_input")
hidden1 = keras.layers.Dense(30, activation="relu")(input_B)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
output = keras.layers.Dense(1, name="output")(concat)
model = keras.models.Model(inputs=[input_A, input_B], outputs=[output])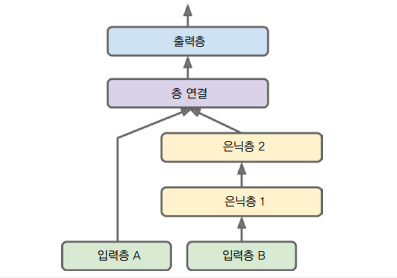
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
X_train_A, X_train_B = X_train[:, :5], X_train[:, 2:]
X_valid_A, X_valid_B = X_valid[:, :5], X_valid[:, 2:]
X_test_A, X_test_B = X_test[:, :5], X_test[:, 2:]
X_new_A, X_new_B = X_test_A[:3], X_test_B[:3]
history = model.fit((X_train_A, X_train_B), y_train, epochs=20,
validation_data=((X_valid_A, X_valid_B), y_valid))
mse_test = model.evaluate((X_test_A, X_test_B), y_test)
y_pred = model.predict((X_new_A, X_new_B))- fit() 호출 시 하나의 입력 행렬을 전달하는 것이 아니라 입력마다 하나씩 행렬의 튜플(X_train_A, X_train_B) 전달
- X_valid 등 다른 경우도 마찬가지
여러 개의 출력이 필요한 경우
-
여러 출력이 필요한 작업 - 그림에 있는 주요 물체를 분류하고 위치를 알아야하는 경우 (회귀+분류)
-
동일한 데이터에서 독립적인 여러 작업 수행시 - 얼굴 사진으로 다중 작업 분류 수행(한 출력은 표정, 다른 출력은 안경 여부)
-
규제 기법으로 사용하는 경우 - 신경망 구조 안에 보조 출력 추가
10. 2. 5 서브클래싱 API로 동적 모델 만들기
시퀀셜 API와 함수형 API는 선언적임
- 사용할 층과 연결 방식을 먼저 정의해야함
- 그 다음 모델에 데이터를 주입하여 훈련이나 추론을 시작함
- 모델을 저장하거나 복사/공유하기 쉬운 방법
- 또한 모델의 구조를 출력하거나 분석하기 좋음
- 프레임워크가 크기를 짐작하고 타입을 확인하여 에러을 일찍 발견할 수 있음
- 전체 모델이 층으로 구성된 정적 그래프이므로 디버깅이 쉬움
서브클래싱 API
- 모델이 반복문을 포함하고 다양한 크기를 다루어야 하며 조건문을 가지는 등
- 여러가지 동적인 구조를 필요로 하는 경우,
- 명령형 프로그래밍 스타일이 필요하다면 서브클래싱 API 사용
class WideAndDeepModel(keras.models.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
model.compile(loss="mse", loss_weights=[0.9, 0.1], optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit((X_train_A, X_train_B), (y_train, y_train), epochs=10,
validation_data=((X_valid_A, X_valid_B), (y_valid, y_valid)))
total_loss, main_loss, aux_loss = model.evaluate((X_test_A, X_test_B), (y_test, y_test))
y_pred_main, y_pred_aux = model.predict((X_new_A, X_new_B))
model = WideAndDeepModel(30, activation="relu")- Input 클래스의 객체를 만들 필요없이 call() 메서드의 input 매개변수를 사용
- 생성자에 있는 층 구성과 call() 메서드에 있는 정방향 계산을 분리함
- call() 메서드 안에서 원하는 어떤 계산도 사용할 수 있음
- 모델 구조가 call() 안에 숨겨져 있으므로 케라스가 쉽게 이를 분석할 수 없음 -> 모델을 저장하거나 복사할 수 없음
- 유연성이 높지만, 실수가 발생하기 쉬움
10. 2. 6 모델 저장과 복원
모델 저장
시퀀셜 API와 함수형 API를 사용하면 훈련된 케라스 모델을 저장하는 것은 다음과 같이 간단함
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
model.save("my_keras_model.h5")
모델을 로드하고 예측
model = keras.models.load_model("my_keras_model.h5")
model.predict(X_new)
10. 2. 7 콜백 사용하기
훈련이 몇 시간 지속되는 경우 (특히 대규모 데이터셋에서 훈련할 때) 훈련 도중 일정 간격으로 체크포인트를 저장해야 함 -> 콜백 사용
fit() 메서드의 callbacks 매개변수를 사용하여 케라스가 훈련의 시작이나 끝에 호출할 객체 리스트를 지정할 수 있음
- ModelCheckpoint는 훈련하는 동안 일정한 간격으로 모델의 체크포인트를 저장함
- 기본적으로 매 epoch의 끝에서 호출됨
# 모델 생성 및 컴파일
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 체크포인트 저장
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only=True)
history = model.fit(X_train, y_train, epochs=10,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb])
# 모델 로드 및 평가
model = keras.models.load_model("my_keras_model.h5") # rollback to best model
mse_test = model.evaluate(X_test, y_test)
ModelCheckpoint의 save_best_only=True로 최상의 검증 세트 점수에서만 모델을 저장
- 오랜 훈련시간으로 훈련 세트에 과대적합될 걱정을 하지 않아도 됨
또는 EarlyStopping 콜백 사용 가능
- 일정 epoch 동안 검증 세트에 대한 점수가 향상되지 않으면 훈련을 멈춤
- 선택적으로 최상의 모델을 복원할 수도 있음
- 페크포인트 저장 콜백과 진전이 없는 경우 훈련을 일찍 멈추는 콜백을 함께 사용할 수 있음
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10,
restore_best_weights=True)
history = model.fit(X_train, y_train, epochs=100,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, early_stopping_cb])
mse_test = model.evaluate(X_test, y_test)- EarlyStopping 콜백이 훈련이 끝난 후 최상의 가중치를 복원하기 때문에 저장된 모델을 따로 복원할 필요 없음
10. 2. 8 텐서보드를 사용해 시각화하기
텐서보드 : 인터렉티브 시각화 도구
- 훈련하는 동안 학습 곡선을 그리거나
- 여러 실행 간의 학습 곡선을 비교하고
- 계산 그래프 시각화와 훈련 통계 분석을 수행할 수 있음
- 모델이 생성한 이미지를 확인하거나
- 3D에 투영된 복잡한 다차원 데이터 시각화하고
- 자동으로 클러스터링 해주는 등의 기능 제공
텐서보드를 사용하려면 이벤트 파일이라는 이진 로그 파일에 시각화하려는 데이터를 출력해야함
- 각각의 이진 데이터 레코드를 서머리summary 라고 부름
- 텐서보드 서버는 로그 디렉토리를 모니터링하고 변경사항을 읽어 그래프를 업데이트함
- 일반적으로 텐서보드 서버가 루트 로그 디렉토리를 가리키고 프로그램은 실행할 때마다 다른 서브디렉토리에 이벤트를 기록함
텐서보드 로그를 위한 루트 로그 디렉토리 정의 및 서브디렉토리 경로 생성 함수
import os
root_logdir = os.path.join(os.curdir, "my_logs")
def get_run_logdir():
import time
run_id = time.strftime("run_%Y_%m_%d-%H_%M_%S")
return os.path.join(root_logdir, run_id)
run_logdir = get_run_logdir()
run_logdir
텐서보드 콜백을 통한 로그 저장
# 모델 정의
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=[8]),
keras.layers.Dense(30, activation="relu"),
keras.layers.Dense(1)
])
model.compile(loss="mse", optimizer=keras.optimizers.SGD(lr=1e-3))
# 텐서보드
tensorboard_cb = keras.callbacks.TensorBoard(run_logdir)
# 모델 훈련
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5", save_best_only=True)
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid),
callbacks=[checkpoint_cb, tensorboard_cb])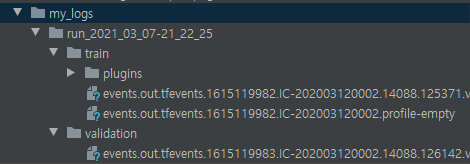
- TensorBoard() 콜백이 로그 디렉토리를 생성하고
- 훈련하는 동안 이벤트 파일을 만들고 서머리를 기록함
텐서보드 서버 실행
$ tensorboard --logdir=./my_logs --port=6006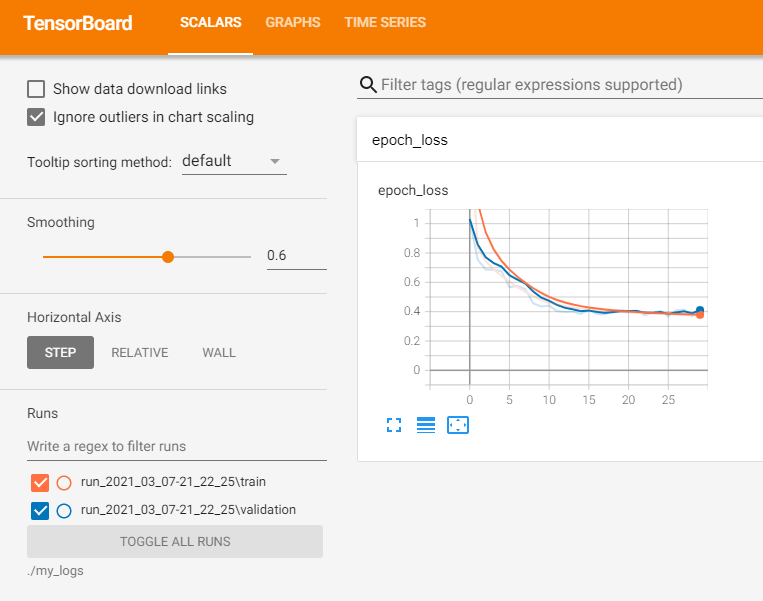
[AI/Hands-on ML] - [핸즈온 머신러닝] 10장 - 케라스를 사용한 인공 신경망 3 (하이퍼파라미터 튜닝)