[핸즈온 머신러닝] 6장 - 결정 트리
6. 결정 트리(decision tree)
- SVM처럼 분류와 회귀 작업, 그리고 다중출력 작업도 가능한 머신러닝 알고리즘
- 매우 복잡한 데이터셋도 학습할 수 있는 강력한 알고리즘
(2장에서 캘리포니아 주택 가격 데이터셋을 완벽하게 맞추는 DecisionTreeRegressor 모델 훈련)
- 가장 강력한 ML 알고리즘 중 하나인 랜덤 포레스트의 기본 구성 요소
6.1 결정 트리 학습과 시각화
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
X = iris.data[:, 2:] # 꽃잎의 길이와 너비
y = iris.target
tree_clf = DecisionTreeClassifier(max_depth=2, random_state=42)
tree_clf.fit(X, y)=> DecisionTreeClassifier(max_depth=2, random_state=42)
from graphviz import Source
from sklearn.tree import export_graphviz #conda install python-graphviz
export_graphviz(
tree_clf,
out_file=os.path.join(IMAGES_PATH, "iris_tree.dot"),
feature_names=iris.feature_names[2:],
class_names=iris.target_names,
rounded=True,
filled=True
)
Source.from_file(os.path.join(IMAGES_PATH, "iris_tree.dot"))=>

※ export_graphviz 수행시 ExecutableNotFound 에러
=>conda install python-graphviz 로 해결
6.2 예측하기
- 위 붓꽃의 품종을 분류하는 결정 트리가 예측하는 방법
- 루트 노드에서 꽃잎의 길이가 2.45cm보다 짧다면, 왼쪽 자식 노드로 이동(깊이1, 왼쪽 노드)
- 이 노드가 리프 노드(자식 노드를 가지지 않는 노드)이므로 Iris-Setosa 클래스로 예측
- 루트노드에서 꽃잎의 길이가 2.45cm보다 길다면, 오른쪽 자식 노드로 이동
- 이 노드는 리프 노드가 아니므로 추가로 검사
- 꽃잎의 너비가 1.75cm보다 작다면 Iris-Versicolor(깊이2, 왼쪽 노드)
- sample 속성 - 얼마나 많은 훈련 샘플이 적용되었는가
- (깊이1, 오른쪽) 100개의 훈련 샘플의 꽃잎 길이가 2.45cm보다 김
- (깊이2, 왼쪽) 그 중 54개 샘플의 꽃잎 너비가 1.75보다 짧음
- (깊이1, 오른쪽) 100개의 훈련 샘플의 꽃잎 길이가 2.45cm보다 김
- value 속성 - 노드에서 각 클래스에 얼마나 많은 훈련 샘플이 있는가
- (맨 오른쪽 아래 노드) Iris-Setosa 0개, Iris-Versicolor 1개, Iris-Virginica 45개
- gini 속성 - 불순도 측정
- 한 노드의 모든 샘플이 같은 클래스에 속해 있다면 이 노드를 순수(gini=0)하다고 함
- (깊이1, 왼쪽 노드)는 Setosa 훈련 샘플만 가지므로 순수 노드이며 gini 점수가 0
- (깊이2, 왼쪽 노드)의 gini 점수는 1-(0/54)^2-(49/54)^2-(5/54)^2 ≈ 0.168
- 아래 식에서 P_i,k는 i번째 노드에 있는 훈련 샘플 중 클래스 k에 속한 샘플의 비율

- 결정 트리의 장점 중 하나는 데이터 전처리가 거의 필요하지 않다는 것
(특성의 스케일을 맞추거나 평균을 원점에 맞추는 작업이 필요하지 않음)
- 사이킷런은 이진 트리만 만드는 CART 알고리즘을 사용
- 리프 노드 외의 모든 노드는 자식 노드를 두개 씩 가짐(yes or no)
- ID3 같은 알고리즘은 둘 이상의 자식 노드를 가진 결정 트리를 만들 수 있음

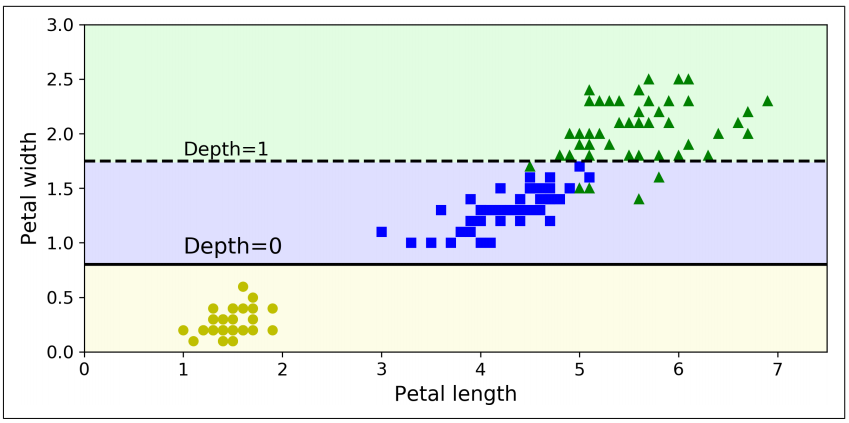
- 결정 트리의 결정 경계
- 굵은 수직선이 루트 노드(깊이 0)의 결정 경계를 나타냄 => 꽃잎 길이=2.45cm
- 왼쪽 영역은 순수 노드(Setosa만 존재)이므로 더 이상 나눌 수 없음
- 오른쪽 영역은 순수 노드가 아니므로 깊이 1의 오른쪽 노드는 꽃잎 너비=1.75cm에서 나누어짐 (파선)
- max_depth가 2이므로 결정 트리는 더 분할되지 않음
- max_depth가 3이면 깊이 2의 두 노드가 각각 (점선처럼) 결정 경계를 추가로 만듦
※ 모델 해석 : 화이트박스와 블랙박스
- 화이트박스 모델
-
결정 트리와 같이 직관적이고 결정 방식을 이해하기 쉬운 모델
- 블랙 박스 모델
-
랜덤 포레스트나 신경망
-
성능이 뛰어나고 예측을 만드는 연산 과정을 쉽게 확인할 수 있지만
-
왜 그런 예측을 만드는지 쉽게 설명하기 여러움
-
ex) 신경망이 어떤 사람이 사진에 있다고 판단했을 때 무엇이 이런 예측을 낳게 했는지 파악하기 어려움
6.3 클래스 확률 추정
결정 트리는 한 샘플이 특정 클래스 k에 속할 확률을 추정할 수도 있음
- 이 샘플에 대해 리프 노드를 찾기 위해 트리를 탐색
- 그 노드에 있는 클래스 k의 훈련 샘플의 비율을 반환
- 길이가 5cm이고 너비가 1.5cm인 꽃잎을 발견했다고 가정했을 때,
- 이에 해당하는 리프 노드는 (깊이 2, 왼쪽 노드)이므로 결정 트리는 그에 해당하는 확률을 출력
- 즉, Setosa 0% (0/54), Versicolor 90.7% (49/54), Virginica 9.3% (5/54)
- 클래스를 하나 예측한다면 가장 높은 확률을 가진 Iris-Versicolor(클래스1)를 출력할 것
tree_clf.predict_proba([[5, 1.5]])=> array([[0. , 0.90740741, 0.09259259]])
tree_clf.predict([[5, 1.5]])=> array([1])
- 추정된 확률은 [결정 트리의 결정 경계] 그래프의 오른쪽 아래 사각형 안에서는 어느 위치든 동일
- 길이가 6cm, 너비가 1.5cm인 꽃잎도 위 예시와 확률이 같음 (Virginica에 더 가까워 보이지만)
tree_clf.predict_proba([[6, 1.5]])=> array([[0. , 0.90740741, 0.09259259]])
6.4 CART 훈련 알고리즘
사이킷런은 결정 트리를 훈련시키기 위해 (트리를 성장시키기 위해) CART(classification and regression tree) 알고리즘을 사용
- 훈련 세트를 하나의 특성 k의 임계값 t_k를 사용해 두 개의 서브셋으로 나눔 (ex. 꽃잎의 길이 <= 2.45cm)
- k와 t_k를 고르는 방법
- (크기에 따른 가중치가 적용된) 가장 순수한 서브셋으로 나눌 수 있는 (k, t_k) 짝을 찾음

- CART 알고리즘이 훈련 세트를 성공적으로 둘로 나누었다면, 같은 방식으로 서브셋을 또 나누고, 그 후 서브셋의 서브셋을 나누는 방식으로 반복
- 이 과정은 최대 깊이(max_depth)가 되면 중지하거나
- 불순도를 줄이는 분할을 찾을 수 없을 때 멈추게 됨
- 다른 몇 개의 매개변수도 중지 조건에 관여
- min_samples_split, min_sam ples_leaf, min_weight_fraction_leaf, and max_leaf_nodes
※ CART 알고리즘은 탐욕적 알고리즘
- 맨 위 루트 노드에서 최적의 분할을 찾으며 이어지는 각 단계에서 이 과정을 반복
- 현재 단계의 분할이 몇 단계를 거쳐 가장 낮은 불순도로 이어질 수 있을지 없을지 고려하지 않음
- 즉, 최적의 솔루션을 보장하지 않음
- 최적의 트리를 찾는 것은 NP-완전 문제로 알려져 있음
-
이 문제는 O(exp(m)) 시간이 필요
-
매우 작은 훈련 세트에도 적용하기 어려움
-
그러므로 탐욕적 알고리즘으로 만족하는 것이 좋음
6.5 계산 복잡도
예측을 하려면 결정 트리를 루트 노드에서부터 리프 노드까지 탐색해야함
- 일반적으로 결정 트리를 탐색하기 위해서 약 O(log2(m))개의 노드를 거쳐야 함(m: 훈련데이터 수)
- 각 노드는 하나의 특성값만 확인하기 때문에 예측에 필요한 전체 복잡도는 O(log2(m))
=> 큰 훈련 세트를 다룰 때도 예측 속도가 매우 빠름
훈련 알고리즘은 각 노드에서 모든 훈련 샘플의 모든 특성을 비교함(max_features 지정시 그 보다는 적은)
- 각 노드에서 모든 샘플의 모든 특성을 비교하면 훈련 복잡도는 O(n x mlog2(m))
- 훈련 세트가 작을 경우(수천 개 이하) 사이킷런은 미리 데이터를 정렬하여 훈련 속도를 높일 수 있음(presort=True)
* 사이킷런 0.21버전에서 히스토그램 기반 그레이디언트 부스팅이 추가되었고 presort 매개변수로 얻을 수 있는 성능 향상이 크지 않기 때문에 사이킷런 0.24버전에서 결정 트리와 그레이디언트 부스팅 클래스의 presort 매개변수가 삭제되었음
6.6 지니 불순도 또는 엔트로피?
지니 불순도
- 기본적으로 사용
- DecisionTreeClassifier의 criterion 매개변수 기본 값은 "gini"
엔트로피 불순도
- criterion 매개변수를 "entropy" 로 지정
- 열역학 개념에서, 분자가 안정되고 질서 정연하면 엔트로피가 0에 가까움
- 메시지의 평균 정보 양을 측정하는 섀넌의 정보이론에서, 모든 메시지가 동일하면 엔트로피가 0
- 머신러닝에서는 불순도의 측정 방법으로 자주 사용
- 어떤 세트가 한 클래스의 샘플만 담고 있다면 엔트로피가 0
- 깊이 2의 왼쪽 노드의 엔트로피는 − (49/54) x log2(49/54) − (5/54) x log2(5/54) ≈ 0.445

※ 지니 불순도와 엔트로피 중 어떤 것을 사용해야하는가
- 실제로 큰 차이가 없으며, 비슷한 트리를 만들어냄
- 지니 불순도가 조금 더 계산이 빠르므로 기본값으로 좋음
- 다른 트리가 만들어지는 경우
-
지니 불순도가 가장 빈도 높은 클래스를 한쪽 가지로 고립시키는 경향이 있는 반면
-
엔트로피는 조금 더 균형 잡힌 트리
6.7 규제 매개변수
결정 트리는 훈련 데이터에 대한 제약 사항이 거의 없음 (선형 모델은 데이터가 선형일 거라 가정하는 반면)
제한을 두지 않으면 트리가 훈련 데이터에 아주 가깝게 맞추려 해 과대적합되기 쉬움
- 결정 트리는 모델 파라미터가 없는 것이 아니라(보통 많음)
- 훈련되기 전에 파라미터 수가 결정되지 않음 => 비파라미터 모델
- 모델 구조가 데이터에 맞춰져서 고정되지 않고 자유로움
- 파라미터 모델(ex. 선형 모델)은 미리 정의된 모델 파라미터 수를 가짐
- 자유도가 제한되며, 과대적합될 위험이 줄어듬
- 과소적합될 위험은 커짐
훈련 데이터에 대한 과대적합을 피하기 위해 학습할 때 결정 트리의 자유도를 제한할 필요가 있음 => 규제
- 규제 매개변수는 사용하는 알고리즘에 따라 다르지만
- 적어도 결정 트리의 최대 깊이는 제어 가능
- 사이킷런의 max_depth 매개변수(기본값=None, 제한 없음)
- max_depth를 줄이면 과대적합의 위험 감소
DecisionTreeClassifier의 결정 트리의 형태를 제한하는 매개변수들
- min_samples_split : 분할되기 위해 노드가 가져야 하는 최소 샘플 수
- min_samples_leaf : 리프 노드가 가지고 있어야할 최소 샘플 수
- min_weight_fraction_leaf : min_samples_leaf와 같지만 가중치가 부여된 전체 샘플 수에서의 비율
- max_leaf_nodes : 리프 노드의 최대 수
- max_features : 각 노드에서 분할에 사용할 특성의 최대 수
=> min으로 시작하는 매개변수를 증가시키거나 max로 시작하는 매개변수를 감소시키면 모델에 규제가 커짐

- moons 데이터셋에 훈련시킨 두 개의 결정 트리
- 왼쪽 결정 트리 : 기본 매개변수 사용해 훈련, 규제 없음
- 과대적합되었음
- 오른쪽 결정 트리 : min_samples_leaf=4로 지정하여 훈련
- 일반화 성능이 더 좋을 것으로 보임
※ 가지치기 pruning (제거)
제한 없이 결정 트리를 훈련시키고 불필요한 노드를 가지치기 (= 사후 가지치기)
- 순도를 높이는 것이 통계적으로 큰 효과가 없다면 리프 노드 바로 위의 노드는 불필요할 수 있음
- 대표적으로 카이제곱 검정 같은 통계적 검정을 사용하여 순도 향상이 우연히 향상된 것인지 추정(귀무가설)
- 이 확률을 p-값이라고 부름
- p-값이 어떤 임계값보다 높으면 그 노드는 불필요한 것으로 간주, 그 자식노드 삭제
- 임계값은 하이퍼파라미터로 조정되지만, 통상적으로 5%
- 가지치기는 불필요한 노드가 모두 없어질 때까지 계속됨
6.8 회귀
- 결정 트리를 회귀 문제에 사용할 수 있음
- 사이킷런의 DecisionTreeRegressor를 사용해, 잡음 섞인 2차 함수 형태의 데이터셋에서 max_depth=2 설정으로 회귀 트리 훈련
# Quadratic training set + noise
np.random.seed(42)
m = 200
X = np.random.rand(m, 1)
y = 4 * (X - 0.5) ** 2
y = y + np.random.randn(m, 1) / 10
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor(max_depth=2)
tree_reg.fit(X,y)
export_graphviz(
tree_reg1,
out_file=os.path.join(IMAGES_PATH, "regression_tree.dot"),
feature_names=["x1"],
rounded=True,
filled=True
)
Source.from_file(os.path.join(IMAGES_PATH, "regression_tree.dot")) =>

각 노드에서 클래스를 예측하는 대신 어떤 값을 예측함
- x1=0.6인 샘플의 타깃 값을 예측한다고 가정
- 루트 노드부터 시작해 트리를 순회하면 value=0.111인 리프 노드에 도달하게 됨
- 이 리프 노드에 있는 110개 훈련 샘플의 평균 타깃값이 예측값이 됨
- 이 예측값을 사용해 110개 샘플에 대한 MSE(평균제곱오차)를 계산하면 0.015

max_depth=3으로 설정하면 오른쪽 그래프와 같은 예측을 얻게됨
- 각 영역의 예측값은 항상 그 영역에 있는 타깃값의 평균
- 알고리즘은 예측값과 가능한 한 많은 샘플이 가까이 있도록 영역을 분할
CART 알고리즘
- 훈련 세트를 불순도를 최소화하는 방향으로 분할하는 대신 평균제곱오차(MSE)를 최소화하도록 분할하는 것을 제외하고는 앞서 설명한 것과 비슷하게 작동

- 분류에서와 같이 회귀 작업에서도 결정 트리가 과대적합되기 쉬움

- 규제가 없다면 왼쪽과 같은 예측
- 훈련 세트에 크게 과대적합되었음
- min_samples_leaf=10으로 지정한 오른쪽 그래프
- 어느정도 일반화가 된 모델
6.9 불안정성
- 결정 트리는 해석하기 쉬우며, 사용하기 편하고, 여러 용도로 사용할 수 있으며 뛰어난 성능을 보여줌
- 하지만 몇 가지 제한 사항이 존재
1. 결정 트리는 계단 모양의 결정 경계를 만듦 (모든 분할은 축에 수직) => 훈련 세트의 회전에 민감함

- 선형으로 구분될 수 있는 데이터 셋 예시
- 왼쪽 결정트리는 쉽게 데이터셋을 구분
- 데이터셋을 45도 회전한 오른쪽 결정 트리는 불필요하게 구불구불해짐
- 두 결정 트리 모두 훈련 세트를 완벽하게 학습하지만 오른쪽 모델은 잘 일반화되지 않을 것
-> 이 문제를 해결하기 위해 훈련 데이터를 더 좋은 방향으로 회전시키는 PCA 기법 사용
※ PCA (주성분 분석, Principal Component Analysis)
고차원의 데이터를 저차원의 데이터로 축소시키는 차원 축소 방법 중 하나
여러 데이터들이 하나의 분포를 이룰 때 이 분포의 주 성분을 분석하는 방법으로, 주성분은 그 방향으로 데이터들의 분산이 가장 큰 방향벡터를 의미
2. 훈련 데이터에 있는 작은 변화에 매우 민감
- 훈련 세트에서 가장 넓은 Iris-Versicolor (꽃잎 길이=4.8cm, 너비=1.8cm 인 것)를 제거하고 결정 트리를 훈련하면 위와 같은 모델을 얻게됨
- 6.2절에서 만들었던 결정트리와 매우 다른 모습
- 사이킷런에서 사용하는 훈련 알고리즘은 *확률적이기 때문에 (random_state 매개변수 미지정시) 같은 훈련 데이터에서도 다른 모델을 얻을 수 있음
(*각 노드에서 평가할 후보 특성을 무작위로 선택함)
=> 다음 장의 랜덤 포레스트는 많은 트리에서 만든 예측을 평균하여 이런 불안정성 극복
참고
hands-on ml2 git
github.com/ageron/handson-ml2/blob/master/06_decision_trees.ipynb
CART
PCA
bkshin.tistory.com/entry/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-9-PCA-Principal-Components-Analysis